② 파라미터 탭¶
Parameters 탭은 모델링 및 평가 설정을 제어합니다 — 허용할 Maxent 피처 클래스, 정규화 배수, 공간 교차검증 방식, 출력 경로. 기본값은 정립된 Maxent 관행을 따르며, 본 장에서는 각 컨트롤이 무엇을 하고 언제 기본값을 변경해야 하는지 설명합니다.
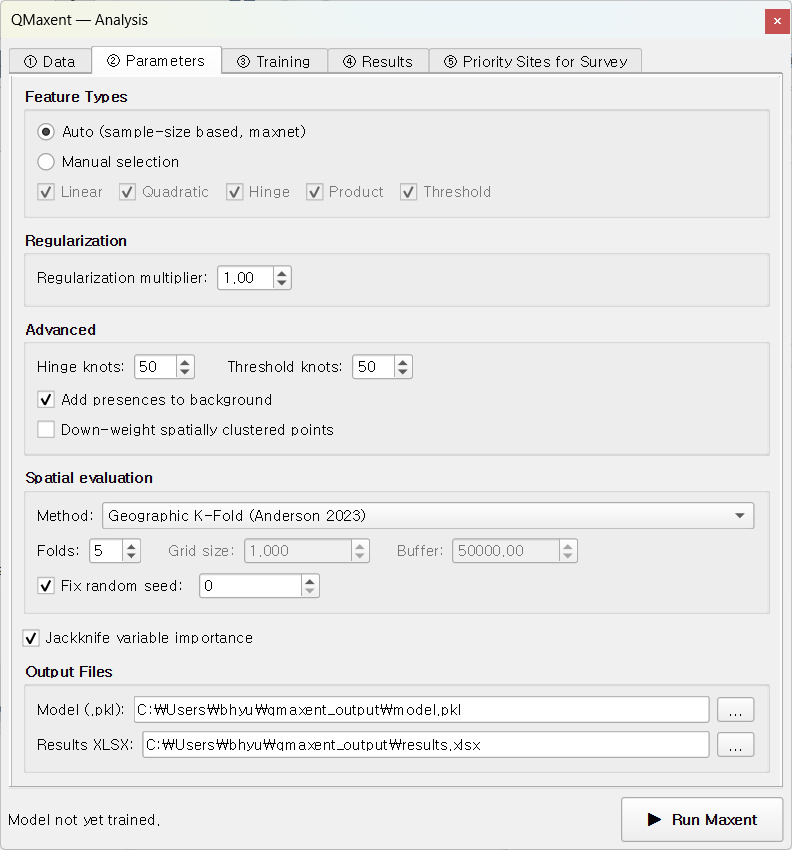
피처 유형¶
Maxent의 "피처"는 각 환경 변수에 대한 적합도 반응을 표현하는 기저 함수입니다. 다섯 개 클래스(LQPHT)는 다음과 같습니다:
| 피처 | 기호 | 표현 |
|---|---|---|
| Linear | bio1 |
단조 선형 반응 |
| Quadratic | bio1² |
최적점 형태 반응 |
| Hinge | max(0, bio1 − threshold) |
조각별 선형 / 매우 유연 |
| Product | bio1 × bio7 |
쌍별 상호작용 |
| Threshold | 1[bio1 > threshold] |
계단 반응 |
Auto (권장)¶
기본값. QMaxent는 R maxnet 패키지가 사용하는 동일한 maxnet 자동 규칙 으로
출현 지점 수에 따라 LQPHT 부분집합을 활성화합니다:
| 출현 점 수 | 활성화되는 피처 |
|---|---|
| ≥ 80 | 모두 (LQPHT) |
| 15–79 | LQH (Product, Threshold 제외) |
| 10–14 | LQ |
| < 10 | L만 |
이 보수적 스케일링은 작은 데이터셋의 과적합을 방지합니다. 116점 Bradypus 예제를 포함한 대부분의 연구에서 기본값은 발표된 관행이 권장하는 그대로입니다 (Radosavljevic & Anderson 2014).
Manual selection¶
Manual selection 을 선택하면 LQPHT의 어떤 조합이든 직접 켜고 끌 수 있습니다. 다음 경우에 유용:
- 다른 발표 연구 재현 — 특정 피처 부분집합을 사용한 경우
- 과적합 진단 — Hinge와 Threshold를 끄면 AUC를 약간 잃지만 더 부드러운 반응곡선
- 민감도 분석 — 어떤 피처 클래스가 예측을 주도하는지 이해
정규화¶
정규화는 Maxent가 계수를 0 쪽으로 얼마나 강하게 줄이는지를 제어합니다 — 분산을 편향과 직접 교환합니다. 배수 가 기본 정규화를 스케일링하며, 1보다 크면 더 부드럽고 단순한 모델, 1보다 작으면 더 가깝게 적합합니다.
| 배수 | 효과 | 사용 시점 |
|---|---|---|
| 0.5 | 더 유연, AUC 높음, 과적합 위험 높음 | 강한 근거와 CV 기반 점검이 있을 때만 |
| 1.0 (기본) | 표준 Maxent 정규화 | 대부분의 연구 |
| 2.0–4.0 | 부드러운 반응, 더 나은 외삽 | 작은 데이터셋, 넓은 환경 그래디언트 투영 |
확신이 없으면 1.0으로 두고 교차검증 AUC를 확인하세요. 학습 AUC가 CV AUC보다 훨씬 높으면 과적합을 시사하며, 더 큰 배수를 시도할 만합니다.
고급¶
| 컨트롤 | 기본 | 비고 |
|---|---|---|
| Hinge knots | 50 | Hinge 피처의 knot 점 수. 거의 변경 불필요. |
| Threshold knots | 50 | Threshold 피처도 동일. |
| Add presences to background | ✓ on | Phillips et al. (2017) 권장: 출현 지점을 배경 표본에 포함하는 것이 통계적으로 더 정확한 정식화. |
| Down-weight spatially clustered points | off | 강한 공간 표본 편향이 있을 때 활성화 (도로변 관찰 등). Phillips et al. (2009)의 거리 가중 편향 보정 구현. |
공간 평가¶
다이얼로그에서 가장 중요한 학술적 결정 — 모델의 예측 성능을 어떻게 측정하는지. QMaxent는 5가지 방법을 제공합니다.
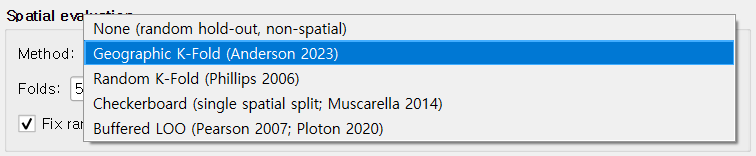
| 방법 | 권장 시점 | 참고문헌 |
|---|---|---|
| None | 빠른 점검만 — 보류 평가 없음 | — |
| Geographic K-Fold (기본) | 일반 사용; ≥ 25 출현 지점 | Anderson 2023 |
| Random K-Fold | 고전 Maxent 논문 재현 | Phillips 2006 |
| Checkerboard | 공간 구조를 가진 단일 결정적 분할 | Muscarella 2014 (ENMeval) |
| Buffered LOO | 작은 데이터셋 (≤ 25 출현 지점) | Pearson 2007; Ploton 2020 |
왜 Geographic K-Fold 가 기본값인가? 출현 지점은 거의 항상 공간적으로 자기상관을 가집니다 — 무작위 폴드는 학습과 검증 점이 옆에 붙어 있게 만들어 AUC를 크게 부풀립니다 (Roberts 2017). 지리적 폴드는 검증 세트가 학습 세트와 공간적으로 분리되도록 강제해 훨씬 정직한 성능 추정을 산출합니다. 더 깊은 논의는 방법론 해설 참고.
Folds, Grid size, Buffer, Fix random seed¶
이 네 개의 수치 입력은 선택한 방법에 따라 조건부로 활성화됩니다:
- Folds: K-Fold 방식의 분할 수. 5(기본)는 대부분 데이터셋에서 편향과 분산을 균형있게 잡습니다.
- Grid size: Checkerboard의 셀 크기, 래스터 단위. 출현 지점들의 일반적 간격에 맞춰 설정.
- Buffer: Buffered LOO의 보류 출현 지점 주변 제외 반경, 미터. 50 km 가 육상 척추동물의 합리적 기본값 — 분산 거리에 따라 더 작거나 큰 값 사용.
- Fix random seed (체크박스 + 값): 재현성을 위해 활성화. 시드는 폴드 구성과 배경 표본 추출에 사용되므로, 같은 시드로 재실행하면 비트 단위로 동일한 결과.
Jackknife 변수 중요도¶
체크하면 QMaxent가 표준 Maxent jackknife 를 계산합니다 — 각 변수에 대해 두 개의 추가 모델을 적합(그 변수만, 그 변수 제외)하고 결과 AUC를 보고합니다. 특징적인 변수별 막대 그래프(④ 결과 탭)를 만들고 Jackknife 시트를 결과 XLSX에 추가합니다.
많은 변수를 가진 모델에서는 학습 시간이 약 2 × (변수 수) + 1 배가 되지만, 일반적인
< 15개 변수의 경우 추가 비용이 작으므로 기본적으로 켜둡니다.
출력 파일¶
모델 실행 시 두 파일이 작성됩니다:
- Model (.pkl): 직렬화된 학습 Maxent 모델(elapid
MaxentModel인스턴스가 Python pickle로). ① Data 탭에서 다시 불러오기. pickle 보안 안내는 모델 저장 및 재사용 참고. - Results XLSX: 실험 설정·변수 목록·교차검증·Jackknife 중요도·우선조사 후보지 출력을 담은 다중 시트 Excel 워크북. 학술 논문 보충 표 관행 형식. 결과 내보내기 참고.
두 경로 모두 홈 디렉터리 아래 qmaxent_output 폴더가 기본값이지만, 쓰기 가능한 어느
위치로든 변경 가능합니다.